


Speech Direct – die medizinische Spracherkennung der nächsten Generation
Spracherkennung
Klinische Dokumentationen binden wertvolle ärztliche Zeit. Befunde, Patientenakten und Korrespondenzen entstehen meist unter enormem Druck und oft erst nach Feierabend. Das führt zu Stress, erhöhter Fehleranfälligkeit bis hin zu Verzögerungen bei der Abrechnung.
Speech Direct wurde entwickelt, um den Dokumentationsaufwand grundlegend zu reduzieren. Unsere KI-gestützte Spracherkennungsplattform ermöglicht es Ärzt:innen, direkt in klinische Anwendungen zu diktieren – ohne separate Software, ohne manuelles Antrainieren eines Sprachprofils und ohne zusätzlichen Arbeitsaufwand. Dies sorgt für spürbare Entlastung im Klinik-Alltag: Dokumentation in Echtzeit bedeutet weniger Schreibaufwand und mehr Zeit für Patient:innen.
Spracherkennung für Krankenhäuser mit nahtloser KIS-Integration
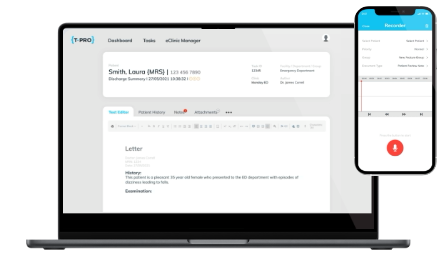
Speech Direct integriert sich lückenlos in bestehende Systeme und unterstützt Anwendungen vollautomatisch. Ob im KIS oder PACS, in Formularen, Masken oder strukturierten Eingabefeldern – Ihr ärztliches Personal kann immer direkt dort diktieren, wo es gerade tätig ist.
Dank erweiterter Sprachbefehle, Autotexte und personalisiertem Vokabular wird die Dokumentation schneller, präziser und konsistenter – im gesamten klinischen Workflow. So sparen sich medizinische Fachkräfte bis zu 75 % ihrer bisherigen Dokumentationszeit.

Spracherkennung

Hoch flexibel, sofort nutzbar
Ob lokal, virtualisiert oder mobil – die Plattform funktioniert auf allen gängigen Infrastrukturen. Jeder Arbeitsplatz wird im Handumdrehen zur Diktierstation. Durch das einheitliche Profil bleibt die Dokumentation stets konsistent.
- Nutzung über PC, Tablet, Smartphone oder Diktiermikrofon
- Sofort einheitliches Sprachprofil auf allen Geräten
- Mobile Diktate von unterwegs oder zwischen Terminen
- Ideal auch für Visiten, Notaufnahme, Ambulanz oder OP-Bereich
Ärztlich geführte Spracherkennung mit optionaler Back-End-Unterstützung
Im klinischen Alltag bleibt die Ärztin oder der Arzt führend im Dokumentationsprozess: Diktate werden direkt im Front-End erstellt, geprüft und freigegeben – strukturiert, effizient und ohne Medienbrüche. Ergänzend kann die Back-End-Erkennung eingesetzt werden, wenn Audiodaten im Hintergrund transkribiert oder weiterverarbeitet werden sollen. In diesem Fall übernimmt das Sekretariat die Nachbearbeitung und Finalisierung der Dokumente. So entsteht ein flexibler Dokumentationsworkflow, der ärztliche Autonomie wahrt und gleichzeitig spürbar entlastet.

Vorteile
Spracherkennung für Krankenhäuser mit Speech Direct
Bis zu 75 % Zeitersparnis bei der Dokumentation
Höhere Produktivität & Datenqualität
Direkte Integration ins KIS – ohne Zusatzsoftware
Sprachgesteuerte Navigation & intuitive Autotexte
Mobil, flexibel & standortunabhängig
Back-End-Erkennung zur Entlastung von Ärzt:innen
Einheitliches Sprachprofil auf allen Geräten
Diktieren in Echtzeit – von der Erstellung bis zur Freigabe im System
Voller Zugriff über Desktop, Tablet und Smartphone
Zu unseren weiteren Leistungen
Kontakt
Wie können wir weiterhelfen?

Nathalie Müller
Business Development
Telefon + 49 (0) 711 – 222 1927
vertrieb@amanu.de